

Abstract
I. Introduction
In the traditional media era, video has played a dominant role among other types.
People can get this by comparing TV with newspaper and radio. Due to the development
of internet and mobile internet, now more and more peoples are accustomed to obtain
information from the internet. Among the type of information, a lot of them are text
or text mixed with other forms of content, such as pictures, audios and videos. Because
the bandwidth improving project in our country and globally, as well as the adoption
of 4G mobile networks, surely people can see video stand still on the hot spot of
media service.
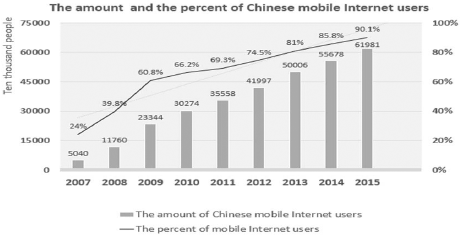
Fig. 1.Fig. 1. General view of chinese mobile internet users
According to the data from CNNIC, the amount of people using mobile internet and short
videos are increasing fast. It is shown in Fig. 1., today there are 750 million people using mobile devices to access the internet.
It is shown in Fig. 2., among them 65.4% are using mobile phones to view videos. Mobile phones with smart
operating system are easy to use nowadays, but little screen and mobility is the advantage
as well as shortage, which decided that short video should be a better form of video
used in them.
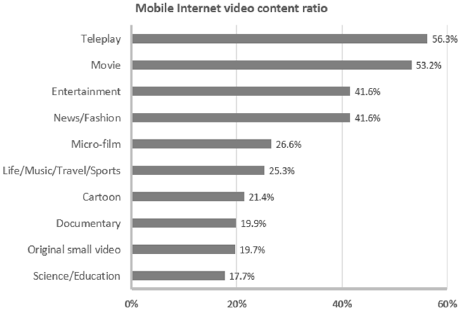
Fig. 2.Fig. 2. Mobile internet video content ratio
Video industry is approaching the point of big changes, the so called big-video era. Beside the traditional long videos, there are more and more short videos, such as fragmented short video news, MVs and micro-movies, produced to satisfy the popularity of mobile devices and mobile internet, as well the fast pace of working and living style. This has stimulated video content providers to provide more short videos to attract mobile users. Because most of mobile phones have camera, not only people could view video content by it, but also they can make video (mostly short video) by themselves and upload the videos to the social media. Some people are trying to form their own UGC (user generated content) studio to produce the half professionalized short video and to provide the short video for the content provider's platform and for the purpose of advertisement.
In recent years there have been a lot sentiment analysis works about the social media
such as Weibo (Micro-blog) [1]. But there are few towards online short videos. Because new media institute is a
the main stream media research center in domestic media domain, many short video providers
want it to setup a specified online short video analyzing system, to provide them
the analyzing result of the user's attitude towards the short videos (mainly the comments).
The system has been built since 2014. It is shown in Fig.3., now a full-functionality system has been put into use, which based on mature technology,
and specialized on online short videos comments data fetching, analyzing and utilizing.
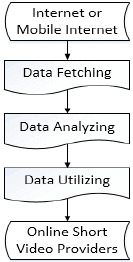
Fig. 3.Fig. 3. System procedure
This article introduces the system as a whole, but focuses on the data fetching part and data analyzing part. The data fetching part utilize mainstream searching technology plus distributed implementation, and the data analyzing part includes robust machine learning technology to fulfill the data mining.
There are mainly five parts in this article: (1) Introduction, (2) Background knowledge, (3) Online short video comments data fetching, (4) Online short video comments data analyzing, (5) Utilization of analyzing result, (6) Future work.
II. Background Knowledge
A. Data Fetching Technology in Related Field
The first step to do data mining is getting enough data, large amount of data means an efficient data fetching system is required. Getting data through the API provided by the website is a common method. However this method has serious limitation in the amount and frequency of getting data.
Due to the development and application of big data technology, now people can use distributed web spider to fetch data straightly. Distributed web spider can get large amount of data in short time and make it more flexible to design crawl strategy.
B. Data Analyzing Technology in Related Field
Online short video comments analyzing is a task similar with other text sentiment analysis. Sentiments analysis was also called opinion mining, which has been widely used in websites, social media for the mining of user's opinion. It has many researches for English text sentiment analysis, and it is popular for Chinese in recent years.
With the help of nowadays big data, sentiment analysis is popular not only because it can help media to push contents to its users, but also it can help websites to recommend products. Sentiment analysis is mainly for two types of text analysis, which are topic related text sentiment analysis and non-topic related sentiment analysis. For topic related text analysis, topic word choosing is very important, but for the purpose of text sentiment analysis, it is not the case. The words representing the polarity of opinion will have the most significance. They are used to extract the attitude and orientation of the comments maker, whether it is positive, approving, neutral, or passive, even antagonistic.
The purpose of the data analysis as a whole is to find out the sentiment polarity of the comments text, and the intensity of the sentiment. Nowadays there are two popular methods for sentiment classification: one way is based on the sentiment knowledge such as lexicon, another is based on machine learning and feature classification.
1) Methods Based on Sentiment Knowledge
Text sentiment analysis has been implemented abroad for many years [2][3]. The methods usually depend on the existed sentiment lexicon as the basis to compute for text sentiment orientation determination [4].
At first, these methods only considering sentiment related words, but it is not sufficient for the consideration of context. So it needs to include adjective or adverb to give the weights of the phrase. People often combine many aspects such as sentiment polarity, intensity, to sum up all the weights of the text, ex. Micro-blog.
2) Methods Based on Machine Learning
Methods based on machine learning usually regards the text analyzing task as a kind of classification task. Firstly, they divided the text attitude which needs to be analyzed as subjective or objective, then they try to extract the polarity of the text sentiment and calculate the intensity.
The main machine learning methods involved SVM (Support Vector Machine), NB (Naive Bayesian), ME (Maximum Entropy), KNN (K-Nearest Neighbor), CRF (conditional random field algorithm), etc.
The advantage of machine learning method includes:
- The training set can be auto-tagged, which reduced the human work.
- Feature weight can be presented with the proper form, such as Boolean value.
- Dimension reduction can be applied to deal with sparse arrays.
- There are many machine learning algorithms to be chosen from. When adopting Boolean value presentation, Naive Bayes algorithm could perform very robustly [5][6].
They usually choose the feature words from the text fetched, then putting them into vectors to demonstrate the characters of the text sentiment. With the help of classifiers, the polarity and the intensity of the text sentiment can be taken out.
III. Online Short Video Comments Data Fetching
A. The Fundamental of Web Spider
Web spiders use initial URL to build a spider queue, push request and get the data of the pages by simulating browsers. Then the web spider parses the downloaded pages to get new URLs, and add them into the spider queue. After finishing the process of current URL, web spiders will get the next URL from the spider queue and repeat the above process. Circles like this form the main structure of the web spider [7].
In online short video comments analyzing system, the breadth-first strategy is used.
It is shown as Fig.4., the web spider will get all the pages in the initial URL queue and then add new
URLs gotten from the pages above in the end of the URL queue. The initial URL queue
is consisted of the URLs of the homepage of micro-video in some mainstream video website.
After getting the URL of every micro-video page, web spider can download the page
and fetch data that meets the requirement.
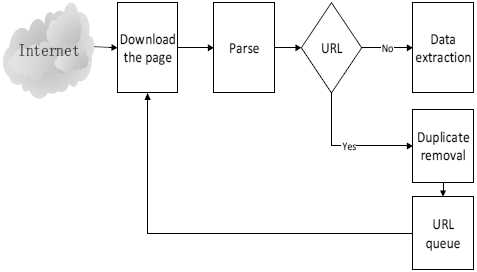
Fig. 4.Fig. 4. Web spider basic flowchart
B. Distributed Implementation
The web spider in this system is a master/slave mode spider based on LAN. Web spider
based on LAN means all the spiders operate in the same LAN and connect each other
by LAN. This method guarantees the high-speed transmission between the different slave
nodes. The master/slave mode web spider assign a host as master node. It is shown
in Fig.5., the host master then assigns task to other slave nodes and gets results. This kind
of web spider is easy to design and maintain [8].
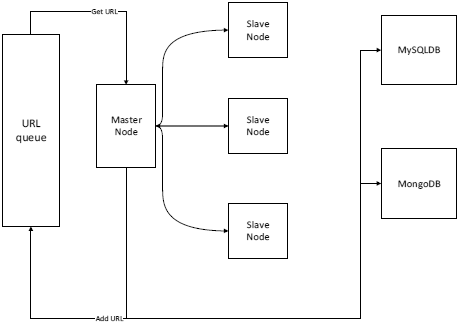
Fig. 5.Fig. 5. Distributed web spider model
C. Data Extraction of the HTML Pages
There is a lot of useless data in the downloaded pages. To get the data meets the requirement data extraction is needed. The system is designed by combining the DOM model and the regular expression.
1) DOM
It is shown in Fig.6., DOM is the Document Object Model. It is a common method to process the HTML document.
By using DOM the system can easily obtain a class of string in the HTML pages. DOM
regards HTML documents as a kind of tree structure. As shown in the figure bellow:
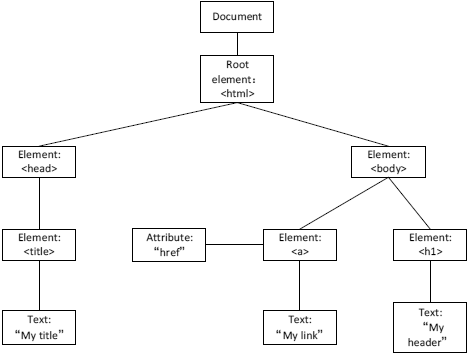
Fig. 6.Fig. 6. HTML document object model
The HTML pages are first transformed into a DOM object. By analyzing the structure of the pages, the positions of the useful data in the page are mapped to the nodes of the DOM object. Setting these nodes in the web spider, it can fetch the needed data and add it into the relevant database [9].
2) Regular Expression
Regular expression is a kind of string which is consisted of a series of specific characters by a designed regular. Regular expression can express some filterable criteria and it is flexible and logic. By using DOM to extract data, there are still many redundant strings such as ‘/t’. Design simple regular expression can filter such interference. Another situation is that there are repetitive nodes and the needed data can't be mapped to the node precisely. In this situation regular expression must be used to point out the precise position [10].
3) Data Types and Storage
The data crawled by the web spider about micro-videos is mainly divided into static data, dynamic data and comments data. Static data includes: title, min, director, protagonist, introduction, release time, poster and type. The dynamic data includes: the amount of playing, like, dislike, comments and the scores. The comments data includes: comments publisher, comments time, comments content, the amount of like for the comments, the amount of reply for the comments, the reply list of the comments. At the part of comments, reply for the comments and the reply for the reply for the comments and so on, breadth-first strategy is also taken and the crawl depth is set as 3.
The static data and the dynamic data from the same video website are saved into two tables of MySQL DB. The comments data is saved into MongoDB because if there are a lot of comments it will be cumbersome in MySQL DB. MongoDB saves data as documents which is consisted of key-value couples. This kind of model is more suitable to handle large amount of data like comments and replies for the comments [11].
IV. Video Comments Data Analyzing
A. Characteristics of Online Short Video Comments Analysis
Firstly, online short video comments analyzing system has very close relationship with NLP (natural language processing), plus Chinese language characteristics. It should deal with words segmentation, words tagging, sometimes even language model.
Secondly, online short video comments analyzing is a kind of sentiment analysis, a task similar with other text sentiment analysis, such Micro-blog, but not always the same.
There are mainly two types of text sentiment analysis, which are topic related text sentiment analysis and non-topic related sentiment analysis.
Topic model is often used for long text data analyzing, but it is not proper to use for short length text analysis tasks such as online short video comments analysis. Online short video comments have their own characteristics:
1) Very Specified
The comments are usually very short, somewhat like Micro-blogs, etc. But they are a little bit formal and only for online short video. And because short videos are widely used in mobile devices, the comments are usually not long and express the user's opinion directly. That is to say, they are specified.
2) Increasing Scale
The scale of online short video comments is smaller than Micro-blog or usual movie comments. This can be seen by Fig.1 and Fig.2 that more people are using mobile devices now, and more people are viewing videos by mobile devices. Due to the popularization of mobile internet, the amount of short video contents and comments shall increase dramatically.
3) Not Topic Related
The comments are towards certain online short video, but they are usually very short (shorter than most of the Micro-blog or other types of comments), direct in expressing opinion, and inattentive to topic, so they can be used as not topic related.
3) Always Subjective
Because of the faster working and living style in current and future society, people attach their comments towards the short videos to express their true attitude. So the comments are always subjective. And it saved our work in preparation work to distinguish whether they are subjective or objective.
B. Preparation Work
Chinese online short video comments analysis is somewhat similar with English counterparts, but it is not always the same. For data analyzing, it has some extra work to do before starting the analyzing procedure.
- Getting comments data from DB following the data fetching part, and putting them into necessary formation .
- Doing Chinese words segmentation .
- Handling stop-word .
Table 1 List of notions

- Using a part-of-speech tagger to identify phrases and key words in the input text which contain adjectives or adverbs [12][13],which is shown in TABLE.1.
- Extracting the expression token little pictures, and get their attitude by label for future use .
For the method in this article, the comments corpora and their corresponding labels are needed to tell whether a comment is positive or passive, during training process. The specified corpora are accumulated in previous work.
C. Algorithm of Comments Analysis
Here the main concern is the online short video comments analyzing part. Among the main two types of analyzing methods, machine learning was chosen for the task. Because of the maturity and widely usage, Naive Bayes is the core of the algorithm.
Naive Bayes is probably one of the most popular machine learning methods. The main function is like this:
Besides the name naive, people can see it is not so naive, so far as you find out the performance of classification. For the irrelevant features of the comments, Naive Bayes can ignore them, and has been proved very robust. The standard Bayes function is like that: \begin{equation*} P(A)\cdot P(B\vert A)=P(B)\cdot P(A\vert B) \tag{1} \end{equation*}P(A)⋅P(B|A)=P(B)⋅P(A|B)(1)
Here C stand for the variable of sentiment, D_{1}D1 stand for positive (abbreviated as ‘post ’), and D_{2}D2 stand for passive (abbreviated as ‘pass ’).
Then it has relationships that can help to retrieve the probability for the data instance of the specified class as follows [14]. \begin{equation*} P(D_{1},D_{2})\cdot P(C\vert D_{1},D_{2})=P(C)\cdot P(D_{1},D_{2}\vert C) \tag{2} \end{equation*}P(D1,D2)⋅P(C|D1,D2)=P(C)⋅P(D1,D2|C)(2)
In real occasion, it is reasonable to make the grant that D_{1}D1 and D_{2}D2 is independent to one another, so it has the function like this: \begin{equation*} P(C\vert D_{1},D_{2})=\frac{P(C)\cdot P(D_{1}\vert C)\cdot P(D_{2}\vert C)}{P(D_{1},D_{2})} \tag{3} \end{equation*}P(C|D1,D2)=P(C)⋅P(D1|C)⋅P(D2|C)P(D1,D2)(3)
Assuming the polarity of the sentiments has two types as positive and passive, the function above changes to: \begin{align*} P(C=^{\prime}{posi}^{\prime} \vert D_{1},D_{2})=\frac{P(C=^{\prime}{posi}^{\prime})\cdot P(D_{1},\vert C=^{\prime}{posi}^\prime)\cdot P(D_{2}\vert C=^{\prime}{posi}^{\prime})}{P(D_{1},D_{2})}\tag{4}\\ P(C=^\prime{pass}^\prime \vert D_{1},D_{2})=\frac{P(C=^{\prime}{pass}^{\prime})\cdot P(D_{1},\vert C=^{\prime}{pass}^{\prime})\cdot P(D_{2}\vert C=^{\prime}{pass}^{\prime})}{P(D_{1},D_{2})}\tag{5} \end{align*}
Then it is the time to choose the parameter which has the biggest possibility: \begin{equation*} C_{most}=\text{arg}\ \text{max}_{c \in C}{P(C}=c)\cdot P(D_{1}\vert C= c)\cdot P(D_{2}\vert C= c) \tag{6} \end{equation*}
In real situation, it often works with probabilities much smaller. And then, it is found in many cases to have more than only two features. Sometimes the accuracy provided by the programming language is also not sufficient. To solve these problems, and to plus the ability to include more features, the log of the probabilities are involved in the function. So the last function has been improved as follows: \begin{equation*} C_{most}= \text{arg}\ \text{max}_{c\in C}(\log P(C=c)+\Sigma_{k}P(D_{k}\vert C=c) \tag{7} \end{equation*}
The theorem for the algorithm is not so complicated, but it is proved very robust and working well. Adding the comments data fetched from the network, the system can analyze and get the results.
Besides the Naive Bayes method, some other methods have already been included to enhance the performance of the analyzing result, such as using Maximum Entropy to find the most suitable result that could match much of the requirements in current situation. The exponential model is similar to the function as follows [15]: \begin{equation*} P_{me}=\frac{1}{N(d)}\exp[\sum_{i}\lambda_{ic}F_{ic}(d,c)] \tag{8} \end{equation*}
V. Utility of Analyzing Result
As a part of a full function system, also a website has been setup for the purpose of serving online short video providers. They can access necessary information, such as the analyzing results by registering for the membership. After approved the member-ships, they could get the renewed information and the graphics demonstrate the result. If necessary, they can get the pushed information through email.
Alongside the analyzing result information providing, a stage is also involved for UGC short video providers to exchange their products, as well as a DRM (Digital Rights Management) to protect the content.
The system can run as full function system with all the features above.
VI. Future Work
The system has run smoothly for at least one year. It is possible to provide domestic short video providers the needed information for them to improve short video products.
By the way, keeping an eye on the latest technical innovation is also necessary for the system's improvement. Because of the development of cloud computing, parallel computing and the utilization of GPU, handling large scale data become much easier now than several years ago. People are using new methods, such as Artificial Neural Networks for sentiment analysis related work. Nowadays deep learning is especially hot.
Due to the fast development of deep learning, now people are trying to using deep neural networks to handle many Graphical as well as NLP problems. Accomplishing the task of sentiment analysis with deep learning is turning into reality [16]. People now use CNNs (Convolution Neural Networks), DBNs (Deep Belief Networks), or other type of deep neural networks to handle Chinese text sentiment classification, such as Micro-blog. The system has been planned to follow this trend, and planned to use the deep-learning method and word embedding to improve online short video comments data analyzing. In the near future, it could serve the short video content providers with better analyzing results by using deep learning.
Acknowledgment
This paper is partly supported by “Research on Technology of Big Data” project, which is funded by the New Media Institute of Communication University of China (14NM06). We thank for all the referees, for their valuable feedback and suggestions to the paper.
References
- [1]F. Neri, C. Aliprandi, F. Capeci, M. Cuadros and T. By, “Sentiment Analysis on Social Media,” Advances in Social Networks Analysis and Mining (ASONAM), 2012 IEEE/ACM International Conference on, Istanbul, 2012, pp. 919–926.
- [2]D. Turney, M. Littman, “Unsupervised Learning of Semantic Orientation from a Hundred-Billion-Word Corpus,” National Research Council of Canada, 2002.
- [3]M. Gamon, A. Aue, “Automatic Identification of Sentiment Vocabulary: Exploiting Low Association with Known Sentiment Terms,” The ACL 2005 Workshop on Feature Engineering for Machine Learning in NLP. Michigan, USA, 2005, pp. 57–64.
- [4]K. Nigam, M. Hurst, “Towards a Robust Metric of Opinion,” Proceedings of the AAAI Spring, Symposium on Exploring Attitude and Affect in Text: Theories and Applications, Stanford, USA, 2003.
- [5]Z. Liu, L. Liu, “Empirical study of sentiment classification for Chinese microblog based on machine learning”, Computer Engineering and Applications, 201248(1)
- [6]H. Yu, V. Hatzivassiloglou, “Towards Answering Opinion Questions: Separating Facts from Opinions and Identifying the Polarity of Opinion Sentences,” Proceedings of the 2003 Conference on Empirical Methods in Natural Language Processing, pp. 129–136.
- [7]J. Huang, J. An, “The research and implementation of Web Spider in Search Engine,” Apperceiving Computing and Intelligence Analysis (ICACIA), 2010 International Conference on, Chengdu, 2010, pp. 244–247.
- [8]H. Gan, “The research and implementation of Web Spider in Search Engine,” Apperceiving Computing and Intelligence Analysis (ICACIA), 2010 International Conference on, Chengdu, 2010, pp. 244–247.
- [9]L. Guangli and Z. Hongbin, “Design of a Distributed Spiders System Based on Web Service,” Web Mining and Web-based Application, 2009. WMWA '09. Second Pacific-Asia Conference on, Wuhan, 2009, pp. 167–170.
- [10]C. Y. Kang, “DOM-Based Web Pages to Determine the Structure of the Similarity Algorithm,” Intelligent Information Technology Application, 2009. IITA 2009. Third International Symposium on, Nanchang, 2009, pp. 245–248.
- [11]C. Zhong, L. Qiyue, L. Jie and W. Jianping, “A programmable controller architecture for regular expression string matching,” Control Conference (CCC), 2012 31st Chinese, Hefei, 2012, pp. 5814–5819.
- [12]C. Gyorodi, R. Gyorodi, G. Pecherle, A. Olah, “A comparative study: MongoDB vs. MySQL,” Engineering of Modern Electric Systems (EMES), 2015 13th International Conference on, Oradea, 2015, pp. 1–6.
- [13]Q. Ye, W. Shi and Y. Li, “Sentiment Classification for Movie Reviews in Chinese by Improved Semantic Oriented Approach,” Proceedings of the 39th Annual Hawaii International Conference on System Sciences (HICSS'06), 2006, pp. 53b-53b.
- [14]L. Coelho, W. Richert, “Building machine learning system with python”, Packt Publishing Ltd., 2013, pp. 126–134
- [15]Z. Niu, Z. Yin and X. Kong, “Sentiment Classification for Microblog by Machine Learning,” Computational and Information Sciences (ICCIS), 2012 Fourth International Conference on, Chongqing, 2012, pp. 286–289.
- [16]X. Sun, F. Gao, C. Li and F. Ren, “Chinese Microblog Sentiment Classification Based on Convolution Neural Network with Content Extension Method,” Affective Computing and Intelligent Interaction (ACII), 201 International Conference on, Xi'an, 2015, pp. 408–4.