

Abstract
1. Introduction
During the last 20 years we have seen several critiques against the “traditional” way of conceiving knowledge and “intelligence”. In particular, the idea that intelligence is individual and dependent upon inner mental functioning has been criticized. So, for instance, Harré [1] proposed that a “second cognitive revolution” has fallen upon us, including new approaches to cognition such as social aspects and the use of artifacts. This idea is (as all ideas) not entirely new, although the labeling “second cognitive revolution” is original. The social founding of intelligence was already stressed in the 1920:s by Russian thinkers, as for instance Vygotsky [2]. This thinking seems to have been revived in the writings of many modern American researchers, who moreover have given it a modern flavor, as well as have added a newer frame of reference. In particular, Edwin Hutchins [3] developed the information processing paradigm for distributed systems and coined the term “distributed cognition”. Hutchins proposed that information processing should be extended to a system, consisting of several people as well as their artifacts. Information is transformed between the nodes in this system and this distributed processing is the kernel of making the system “intelligent”. It should be noted that the artifacts in a system play the same role in the transformation of information as people do. As also proposed by Vygotsky, Hutchins holds that artifacts may be both physical (for instance notes that are exchanged) and psychical (for instance methods for representing or solving problems).
Distributed cognition may thus be seen as both less and more than a symbiosis between users and intelligent systems. It is less, because it does not consider the mutual “nurturing” of two systems. (It may be extended to this, but such a nurturing or development is more in focus in the new developments of “activity theory”, cf Engeström [4], or in the instrumental approach, developed by Rabardel, [5]. It is more, because it provides a framework that enables a computational approach to the interaction between people and their artifacts. In this paper, we will consider a knowledge based system with focus upon the role of explanations as artifacts serving the distribution of information.
Several relations and transformations of knowledge are important for information distribution. First, the knowledge has to be transformed from the expert to the system. Artifacts related to knowledge acquisition may serve in this transformation. Secondly, the information in the system has to be compiled and expressed to the user. This is the essence of a knowledge based system, and relies on computational transformations. Thirdly, the system user takes the expressions from the system and transforms them to (subjective) comprehension. We consider explanations as a joint artifact that serve the transformation process both between the expert and the system and between the system and the ultimate user.
1.1. Problems of explanation and proposed solutions
An explanation has often been regarded as an answer to a “why” question. However, it may equally be regarded in a general way as a link from something to be explained (the explanandum) to some other thing which explains it (the explanans). The link can take different forms, such as a definition, an inclusion relation, or a description of a procedure of how to proceed from one fact to another.
Conceptually, an explanation has two requirements: it should serve as a link between something unknown (or not understood) and something familiar, and it has to be expressed in some way (which excludes pointing). The requirements of being “unknown” and “familiar” imply that for the receivers, explanations are perceived as meaningful, depending upon their prior knowledge. For the providers of explanations, the issue is concerned with how to convey the intended meaning by selecting information to serve the receiver.
The conceptual aspect of explanations offers a way of understanding the problems which have been reported with the practice of providing explanations in knowledge base systems. For instance, why was the earliest practice of only giving a trace of the system’ s reasoning insufficient? (Clancey [6], Southwick [7], Swartout [8]. An answer is that this trace serves system support only, but not system users. A trace of the reasoning is not intended to link familiar concepts to unfamiliar ones, but to support an inference. An inference is only one way of linking concepts. Thus, the trace might contain points which are unfamiliar and which have to be explained further. Or it might contain inference steps that are trivial.
Further, within the distributed perspective, some way of handling the communication requirements has to be found (cf. Kidd & Cooper, [9], Wærn Hägglund Löwgren Rankin, Sokolnicky & Steinemann, [10]).
1.2. Explanation as selection and production
Although explanations between persons can be regarded as formed in a creative process during the dialogue, a more constrained conceptualization has to be used for explanations in artifacts such as books or computers. Here it will be suggested that the provision of explanations can be regarded as a selection process with its own search space. The choice of the concept “search space” facilitates a flexible approach to explanations while keeping within a finite number of explanations. We shall regard explanations as based upon fragments of knowledge that can be related to each other in various ways. The explanation itself is selected from among knowledge fragments, by traversing different links to the explanandum.
There are two main issues to be covered in the selection process. First, the domain itself must be structured in a way that enables the identification of different “knowledge elements” as well as the relationships between these. Secondly, the knowledge elements and their relationships must have some direct connection to a symbolic expression that is comprehensible to a potential recipient. This means that the knowledge to be explained must be represented at a conceptual and communicative level that is most certainly different from the computational level (cf Wærn Hägglund et al [10]).
The explanation process can now be conceptualized as follows. There is an initial entity that has to be explained. This entity may be for instance a fact, a principle, an attribute or a process. The entity possesses several relationships to other entitites (facts, principles, etc.), in the concept structure of the sender as well as in that of the receiver. The aim of the explanation is to find a relationship from the explanandum to the explanans, a relationship that is comprehensible to both the sender and the receiver. The finding of the relationship can be regarded as a “path” in a space between the fact and the explanation goal, a path that may pass through several knowledge elements, and where one or several of these might have to be expressed.
The problem will now consist in representing the entities in the explanans and their relationships to the explanandi in a way that enables them to be expressed comprehensibly to people. Our suggested solution is to represent entities as knowledge elements, linked by conceptual relationships that serve as explanation links. We call this an “explanation network”. The path taken through this network in order to create an explanation is called the “explanation path”.
2. Different ways of structuring the explanation network
In order to solve the dual problem of representing concepts on the one hand and communicating them on the other, we looked for a theory of expert knowledge for the first problem and for a communication theory for the second.
2.1. Theories of expert knowledge
Since an expert system has to enable knowledge to pass from an expert to another person, who might be less expert, a theory of the nature of expert knowledge in relation to nonexpert knowledge is desired.
2.1.1. General aspects
It is obvious that an expert uses knowledge of several different kinds in order to solve a particular problem. This knowledge is based upon general models of the principal actors or concepts in the domain (conceptual models, sometimes also called “mental” models, cf Gentner & Stevens, [11]), as well as upon particular knowledge of causes and effects in special circumstances. This results in a complex structure of knowledge entities, which lie on different levels, and entail different relationships to each other.
It might be considered impossible to describe the structure, since it tends to be “created on the spot” rather than to be fixed in advance (cf Clancey, [12],[6]). Even so, it is apparent that experts have a body of knowledge that is more accessible for solving problems than nonexperts (Jeffries, Turner, Polson & Atwood, [13]). It has also been found that problem specific information is integrated with the relevant domain knowledge (Patel & Groen, [14]). The ease of access can be regarded as a link between the problem at hand and existing domain knowledge, which might be made available to a nonexpert. This will be explored below by using Toulmin's argumentation theory.
2.1.2. Qualitative aspects
It is easy to propose that experts possess more knowledge than non-experts, within their domain of expertise. There also exist qualitative differences in domain knowledge between experts and non-experts. A suggestion for describing these differences in the domain of physics has been put forward by Forbus & Gentner [15] in the Qualitative Process Theory (QPT). Briefly described, Qualitative Process Theory describes how expert knowledge is reached through a learning process ranging from general knowledge to expert knowledge in a specific domain. The learning process is characterized by and consists of several interrelated knowledge-levels. These knowledge levels are:
- Protohistories - Briefly described, protohistories are rich, contextually specific, highly perceptual representations of phenomena, capturing expectations about typical phenomenological patterns. For example “if I turn the key, the car will start”.
- Causal corpus - With the causal corpus the expectations of mechanism enter. Here the representations consists of simple statements that some sort of causal connection exists between variables. (A surface model with rules of thumb for knowledge and problem solving).
- Naive physics (qualitative reasoning) - Processes are introduced to provide the mechanism underlying the causal corpus. That is, the disparate local connections of the causal corpus are replaced with qualitative models organized around the notion of process.
- Expert knowledge (quantitative representations) - Quantitive representations are created.
The learning process to an expert proceeds through these interrelated levels of knowledge with their characteristics, until the level of expert knowledge is reached. Therefore, an individual's knowledge in a specific domain can be more or less described and characterized by the knowledge characteristics described in the model.
It was decided to attempt to construct a structure of the knowledge to be explained in terms of QPT. The success and failure of this attempt will be described later in this article.
2.2. Communication issues
To approach the communication issues, we sought for a conceptualisation which could
express links in the explanation net in an understandable way. We found this conceptualisation
in the so called Rhetorical Structure Theory (RST), proposed by Mann & Thomson [16]. The general idea of RST is that a text has a central part, called the nucleus, which
is related to other parts, called satellites. Different relationships are suggested
between nuclei and satellites, such as justification, concession, enablement. Figure 1 gives an example of an enablement relationship, taken from the domain to be studied,
i.e. protein purification.

Figure 1.Figure 1.
The statement “CIEX is recommended” is here regarded as the nucleus, supported by the satellite “CIEX has high capacity”. This enablement relationship can be used as an explanation for the nucleus statement. Further analyses of RST in relation to knowledge based systems are presented in Rankin [17].
2.3. Selection of explanation path
In order to find an appropriate explanation path, i.e. a path which can be made comprehensible to a human recipient, we turned to Toulmin's argumentation theory.
Toulmin's interest is in “justificatory arguments brought forward in support of assertions” (Toulmin [18], p.12)and he points out that “certain basic similarities of pattern and process can be recognized … among justificatory arguments” (ibid. p. 17). To capture these similarities he presents the following components and structure (with a slight change in terminology in Toulmin Rieke & Janik, [19]):
- Claim -What is being asserted?
- Grounds - On what basis is the claim being made? Warrants -What general rules or principles make the grounds relevant to the claim?
- Backing -What other information can back up a particular warrant. Backing is used to demonstrate that the warrant is sound (ie. reliable) and relevant.
- Modal qualifiers -Warrants may not invariably lead to the required conclusion; qualifications include ‘usually’, ‘possibly’, ‘presumably’, ‘likely’.
- Possible rebuttals -If the claim is not presented as certain or necessary, it may be necessary to mention in what circumstances the claim may not hold (eg. ‘unless the patient is allergic to penicillin’).
Schematically the argument can be represented as follows: Toulmin emphasizes the interdependence
of the various components of the argument: it is not sufficient for the grounds to
be correct, they must also have some bearing on the claim, a requirement found in
the warrant which demonstrates the applicability of the grounds to a given claim.
![Graphic: Schematic Model of an Argument (from Rankin & Harrius, [20])](https://csdl-images.ieeecomputer.org/proceedings/hicss/2004/2056/05/figures/1265332-fig-2-source.gif)
Fig 2.Fig 2.
Likewise the backing provides support to the soundness of the warrant and consists of scientific facts in the domain. It must be made clear whether the claim is being made as a necessary conclusion, a reliable assumption, a mere possibility or whatever, as expressed by appropriate qualifiers. Rebuttals point to special circumstances under which the claim may not hold.
Figure 3, taken from the domain approached here is an example of how an argumentative explanation
can be analyzed
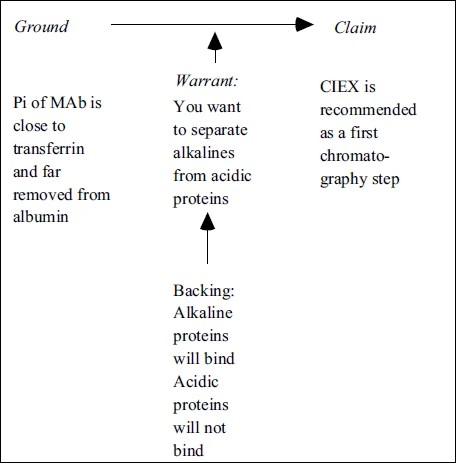
Fig. 3.Fig. 3.
3. Characteristics of the domain chosen
We shall approach the issue of creating an explanation network and testing this within a particular domain, i.e protein purification. All further examples will be taken from this domain. Therefore, a short introduction to the domain will be given first.
3.1. Protein characteristics
Proteins are very powerful elements in all living matter, due to their inherent biological specificity. In order to determine the structural and functional characteristics of protein, they need to be isolated from their biological source material and be separated from contaminating proteins and other organic material.
Protein purification is a typical planning problem. The object is to find an operation or sequence of operations, that will transfer the starting material to a final state defined as the desired end-product. Typically such a planning is based on experience and rule of thumbs rather than an exact knowledge of proteins behaviour during such operations. Planning of protein purification has been found to be a suitable domain when developing expert system applications (Eriksson, Sandahl, Forslund & Osterlund, [21], Ericsson, Sandahl, Brewer & Osterlund, [22]).
3.2. MAbAssistant
MAbAssistant is a planning system that guides the user in how to purify monoclonal antibodies (Brewer, Lundström Sparrman & Osterlund, [23]). Monoclonal antibodies are proteins with a known biological function and with certain common physical and chemical characteristics. Any additional data can be entered and a full search for suitable purification techniques is done. The techniques are rated and fall into one of three classes, to be avoided, where they are acceptable and where they can be recommended for use. The users (who are trained and knowledgeable laboratory assistants) can now ask for explanations of the ratings and can, based on the reasoning of the system, choose a suitable purification plan. During the remaining sessions, separation media are rated and a method can be generated. If the predicted method does not generate the expected separation results, the user can return for a diagnostic search and find suitable remedies for the symptom.
The present work deals only with the initial strategic session, where the evaluation of techniques is intended to be transparent to the user through explanation in text format.
Users' spontaneous comments on this system as well as one systematic study of its explanations (Waern, Ramberg & Osterlund, [24]) were used as a basis for our continued work.
4. Representing the explanation network
The knowledge base for problem solving was considered insufficient for providing nuanced explanations, and so it had to be amended in different ways. We shall here present one way of constructing an explanation network, based upon Jonni Harrius' work, (Harrius, [25]).
The knowledge sources from which information is selected are: a rule base and a concept hierarchy . The use of the inference rules in the rule base is twofold. They are used for deriving new knowledge and they form knowledge elements in the explanation network. The concept hierarchy describes the inheritance structure of the concepts in the domain. The concepts contain descriptions of common properties of the concept classes. These properties are inherited from the nodes to the leaves. What differentiates our concept hierarchies from traditional ones is the use of such attributes as: elaboration, examples and analogies. These are used both when generating explanations and for documentation of the knowledge base. Both the rule base and the concept hierarchy are extended with relations which are used during the content selection and organisation of the critique. Information required for communication about the relations is also stored in the knowledge base.
The content selection is made with the aid of the Toulmin model. We use a generic description of the Toulmin model which is modified depending on the level of the user and the level of agreement between the user's and the system's solutions (Harrius & Rankin [20]). Depending on how the Toulmin model is modified different types of information are selected, examples are given below. As claim a conclusion in a rule is selected. This is based upon the system presented above, which suggests a particular technique to be chosen, given a particular protein purification problem.
The ground for a claim is one premise for the ground. The premisses do not need to be taken from the latest fired rule, instead the premisses which are closely associated with the given ones from the user could be a better choice . As backing a general rule is often selected, but analogies can also be used. Investigation of how examples can be used is in progress. We use meta-rules as warrants to describe why a certain rule is selected as backing. As qualifier a translated certainty factor of the conclusion should be presented. An example of a rebuttal is a premiss of a rule of the enable/disable type, i.e. a premiss which states the limitations of the rule, e.g. “unless the … is stable …”.
5. The expert's experience of explaining
The problem for an expert does not seem to lie in solving a particular problem in a particular circumstance, but rather in explaining why this particular solution was chosen. This is indicated by the fact that it is difficult to acquire knowledge from experts for the design of knowledge based systems. The expert may not be able to express the knowledge directly, though by applying different kinds of knowledge acquisition methods, a structured way of representing knowledge might still be obtained (cf Olson & Biolsi, [26]). Asking the expert for varied kinds of explanations might be regarded as one way of acquiring knowledge. The rules for constructing explanations may be seen as a kind of conceptual artifact.
In our particular case, the expert's knowledge had already been acquired for constructing the existing knowledge base (the MAbAssistant, as presented above).
The explanation facilities in MAbAssistant are linked to the individual rules. For each case a full depth search is performed and all the rules associated with a particular operation are evaluated. In developing MAbAssistant, a limit of 255 characters for anyone explanation was set, which meant that the full logic behind a rule had to be expressed within this limit.
When attempting to analyze the explanation logic, it became apparent that not only was there a great deal of “silent”, i.e. not explicitly expressed knowledge, there were also conclusions that were anything but apparent to the viewer. In order to realize the depth of the knowledge space, the expert took one particular explanation as his point of departure and made an attempt to write down small pieces of knowledge, formulated in statements and inferences that led him to draw the final conclusion as expressed in the explanation. This exercise revealed a pathway through a number of knowledge modules, where various conclusions could be drawn. The outcomes of each of these modules were then cross-checked in order to come one step closer to the final explanation.
An analysis of many different explanations was then made according to RST, to Toulmin's argumentation theory and to QPT as mentioned above. The expert tried to justify his explanations according to these different theories , but was quite unsuccessful when taking each of these separately. However, an attempt to combine Toulmin and QPT the expert experienced some remarkable insights into the knowledge space.
In parallel, an analysis of the domain and how this could be communicated to end users led to the proposal that the overall domain of knowledge had to be limited in space by definitions of terminology. It was concluded that the end users of MAbAssistant and similar systems should have a certain basic knowledge of protein separation. This knowledge would be supplied as definitions.
Inside the domain, a set of sub-domains could be conceptualized, such as a protein domain, which covered both biological and chemical knowledge, a domain of a specific separation technique, etc. The data entered to specify the problem to the system would activate an inference chain within one particular sub-domain. The result of this inference could then act with other data and rules from other sub-domains to produce new conclusions. The end result of such a system would include the explanation network.
The expert found this to be quite close to the original thinking behind the condensed explanations earlier provided and, interestingly enough, to be similar to the results of the first analysis in terms of a pathway between knowledge modules (presented above). The sub-domain idea was now used by taking different explanations from MAbAssistant and constructing explanation networks to structure these as well as expand upon them when needed. The expert found it quite easy to construct new explanations according to the explanation network model.
6. A study of users' perception of the explanation space
Finally, the explanation space should be tested by some real users. The purpose was to investigate the users' opinions of the explanations, with regard to their comprehension of them, their comprehensibility, etc. This study was performed by Robert Ramberg, and a detailed description of it is given in Ramberg [27]
6.1. Choice of network paths
We decided to choose one problem and one technique and to develop an explanation network around these. This was made in cooperation with the expert. Since the explanation network surrounding one single advice is quite extensive, only some links were (intuitively) chosen for further investigation. The links chosen were the following: 1) links representing a difference between different “levels” of explanations, here called “low level” and “high level” respectively. The “high level claims differed from the low level claims by giving more quantitative data, as suggested by the highest levels of QPT. 2) Links representing the protein process versus the protein characteristics respectively (corresponding to some of the “subdomains” mentioned by the expert above). 3) Links corresponding to grounds and backings.
One example of a problem description and its related various explanation types is given in the appendix.
6.2. Method
6.2.1. Subjects
Subjects attending the study were 21 voluntary laboratory assistants working at Pharmacia with varying experiences from protein purification.
6.2.2. Material
A questionnaire consisting of a problem related to a specific case of protein purification was prepared. (see appendix). Explanation types, techniques possible applicable to the problem at hand, and, finally, questions aiming at capturing the subjects' experiences of the explanation types were also included. (not in appendix). The variables to be rated concerning the explanation types were: perceived educational value, comprehension, novelty and usability. Subjects were also asked to rate their own expertise regarding protein-and technique-knowledge respectively. Finally, the subjects were asked to construct an explanation themselves, one that would stimulate as much learning as possible.
6.3. Results
The results indicate that the explanation types were all experienced as easy to understand. Overall comprehensibility was higher than in a previous study, where the original explanations of the system were tested (Ramberg, [28], Waern, Ramberg, & Osterlund, [24]). The explanation types of “expert level claims” as well as “lower level claims” were rated as significantly more usable than “backing” and “ground” . In terms of educational value, the type “expert level claim” was rated as highest , whereas the “low level claim” was rated as having the highest novelty . In order to find possible effects of expertise, multivariate analyses were performed. In a discriminant analysis, using as discriminating value, it was found that people having a greater expertise preferred expert-level and low-level claim type of explanations. People with lower degree of expertise rated all kinds of explanations high. The ratings were supported by the users' construction of explanations, where the same pattern emerged.
6.4. Discussion
The experimental study shows that the expert could generate explanations with the support of explanation networks. As to the users, the general trend seems to be that people with lower expertise want a broad range of explanations, whereas people with higher expertise prefer concise explanations, pointing to the facts. This finding corresponds to a conclusion voiced by Buschke & Macht [29] regarding the efficiency of explanations. These authors suggest that an explanation does not need to be causal, nor need it answer a “why” question. Their view is that it is elaboration per se which gives explanation its value in terms of learning. The present study suggests a structured approach to explanations which facilitates elaboration in different directions. As long as an expert is able to construct such explanations, it seems possible for non-experts to benefit from those.
7. General discussion and conclusions
The idea of conceptualizing explanations as constructions from an explanation network was found to be both feasible and fruitful. The explanation network is a way of simplifying the complex knowledge of an expert into a structure of knowledge elements, created for explanation purposes. In terms of distributed cognition, the explanation network is a conceptual artifact, jointly used by both the expert(s) and the final user.
We have shown that the expert could apply some of the theoretical abstractions to the particular domain. We have also shown that it is possible to amend the knowledge base with the information needed for creating the relationships to be used for explanations, even though this has to be performed “by hand”. Also, the varying requirements of recipients with different knowledge levels could be shown with the aid of this simple explanation network.
This work opens up some new issues in considering explanations as distributed knowledge. First, the idea of using explanations as a way of knowledge acquisition should be further explored. Secondly, the link found between the conceptual structure and its possible expressions should be explored further. Further visual expressions or other media should be investigated, in terms of multimedia. Thirdly, the differential possibilities of the explanation network should be further explored. We have only touched on a few of the possible explanation paths and small differences in terms of user expertise. Other structures might have to be invented in order to cover greater differences. Although a fully automated way of generating explanations is not (yet) possible, a richer way of representing explanations will give rise to more intensive interactions between users and the system.
Appendix
Problem description
The source is ascites. Your IgG1 MAb has a pI of 6.5 with a pH stability ranging from 2 to 6.8 and a salt stability ranging from 0 to 4.0 and with low hydrophobicity. The goal of your separation is to get a 99% pure solution from 100 mg of original sample.
Explanation types
Grounds (result)
pI of MAb is close to transferrin and far removed from albumin.
Backing (result)
CIEX if used below the pI: alkaline proteins including MAb will bind and resolve in a gradient. Acidic proteins will not bind.
Low level claim (process)
CIEX is performed below the pI of the MAb.
Expert level claim (process)
CIEX is preferably performed at pH= 6.5–0.5 = 6.0.
Grounds (process)
Proteins carry a net positive charge below their pI and will then bind to CIEX.
Backing (process)
CIEX separates by binding positively charged proteins and eluting them by a salt gradient.
Acknowledgements
This work has been supported by grants from the Swedish Board for Research in The Humanities and Social Sciences and the Swedish Board for Technical Development.
References
- [1]HarréR. (1999). The rediscovery of the human mind. In Proceedings of the 50th anniversary conference of the Korean Psychological Association, edited by Uichol Kim, Psychology dept, Chung-ang University, Seoul, Korea. Available at: www.massey.ac.nz/~Alock/virtual.korea.htm.
- [2]Vygotsky, L.S. (1978) Mind in Society. Harvard University Press: London
- [3]Hutchins, E. (1995) Cognition in the wild. Cambridge: MIT press.
- [4]Engeström, Y. (1990). Learning, Working and imagining, twelve studies in activity theory. Helsinki: Orienta-Konsultit.
- [5]Rabardel, P. (2002). People and Technology. http://ergoserv.psy.univ-paris8.fr/.
- [6]Clancey, W.J. (1986). From GUIDON to NEOMYCIN and HERACLES in Twenty Short Lessons: ORN Final Report 1979–1985, the AI Magazine, 40–60.
- [7]Southwick, R.W. (1991). Explaining reasoning: an overview of explanation in knowledge-based systems. The Knowledge Engineering Review, 1–19.
- [8]Swartout, W.R. (1983). XPLAIN: a system for creating and explaining expert consulting programs. Artificial Intelligence, 21, 285–325.
- [9]Kidd, A.L. & Cooper, M.B. (1985). Man-Machine Interface issues in the construction and use of an expert system. International Journal of Man-Machine Studies, 22, pp. 91–102.
- [10]WærnY. , HägglundS. , LöwgrenJ. , Rankin, I. , Sokolnicki, T. and Steinemann, A. (1992). Communication Knowledge for Knowledge Communication. International Journal of Man-Machine Studies, 37, 215–239.
- [11]Gentner, D. & Stevens, A. (Eds). (1983). Mental models. Hillsdale, NJ.: Lawrence Erlbaum.
- [12]Clancey, W. (1983). The Epistemology of a Rule-Based Expert System: a Framework for Explanation, Artificial Intelligence, 20, 215–251.
- [13]Jeffries, R. , Turner, A.T. , Polson, P.G. , & Atwood, M.E. (1981). The processes involved in designing software. In: J.R. Anderson (Ed.)Cognitive skills and their acquisition, Hillsdale, NJ: Erlbaum, 255–283.
- [14]Patel, V.L. & Groen, G.L. (1986). Knowledge based solution strategies in medical reasoning. Cognitive Science, 10, 91–116.
- [15]Forbus, K. & Gentner, D. (1986). Learning physical domains. MachineLearnin, 2, 311–343.
- [16]Mann, W.C & Thompson, S.A. (1986) Relational Propositions in Discourse, in Discourse Processe, s9, pp. 57–90.
- [17]Rankin, I. (1993). Natural language generation in critiquing. The Knowledge Engineering Review, 8, No. 4.
- [18]Toulmin, S. (1958). The Uses of Argument. Cambridge, Ma: Cambridge University Press.
- [19]Toulmin, S. , Rieke, R. & Janik, A. (1979). An Introduction to Reasoning. MacMillan Publishing Company
- [20]Rankin, I. & Harrius, J. (1992). Critique Generation - Language Games, Argumentation and Rhetorical Aggregates. In: Papers from the Third Nordic Conference on Text Comprehension in Man and Machine, LinköpingApril 21–23. Department of Computer and Information Science, Linköping University, 129–140.
- [21]Eriksson, H. , Sandahl, K. , Forslund, G. & Osterlund, B.R. (1991). Knowledge Based Planning for Protein Purification. Chemometrics and Intelligent and Intelligent Laboratory Systems: Laboratory Information Management, 13, 173–184.
- [22]Eriksson, H. , Sandahl, K. , Brewer, J. and Osterlund, B.R. (1991). Reactive Planning for Chromatography. Chemometrics and Intelligent Laboratory Systems: Laboratory Information Management, 13, 185–194.
- [23]Brewer, J. , LundströmH. , Sparrman, M. and Osterlund, B. (1990). Recent advances in high performance LC of proteins. Presented by J.B. at Quatrieme Symposium sur les Technologies de Purification des Proteines, Clermont-Ferrand, France, March 14–16.
- [24]WærnY. Ramberg, R. & Osterlund, B. (1995). On the role of explanations in understanding a complex domain. Zeitschrift für Psychologie, 203, pp. 245–258
- [25]Harrius, J. (1993). An architecture and a knowledge representation model for expert critiquing systems. Licentiate Thesis No. 383, Department of Computer and Information Science, Linköping University, Sweden.
- [26]Olson, J.R. & Biolsi, K.J. Techniques for representing expert knowledge. In: K.A. Ericsson & Jacqui Smith (Eds.)Toward a general theory of expertise. Prospects and Limits. Cambridge: Cambridge University Press, 240–285.
- [27]Ramberg, R. (1995). Construing and testing explanations in a complex domain. Computers in Human Behavior, 12 (1), pp. 29–48.
- [28]Ramberg, R. (1992). Explanation? Yes, please! A psychological study of explanations within situations of asynchronic interaction. Thesis presented in partial fulfillment of the degree of Licentiate of Philosophy. Department of Psychology, Stockholm University.
- [29]Buschke, H. & Macht, M. (1983). Explanation and conceptual memory. Bulletin of the Psychonomic Society, 2, 397–399.